Learning from 10 Demos: Generalisable and Sample-Efficient Policy Learning with Oriented Affordance Frames
Abstract
Imitation learning has unlocked the potential for robots to exhibit highly dexterous behaviours. However, it still struggles with long-horizon, multi-object tasks due to poor sample efficiency and limited generalisation. Existing methods require a substantial number of demonstrations to cover possible task variations, making them costly and often impractical for real-world deployment. We address this challenge by introducing \emph{oriented affordance frames}, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data.
Overview
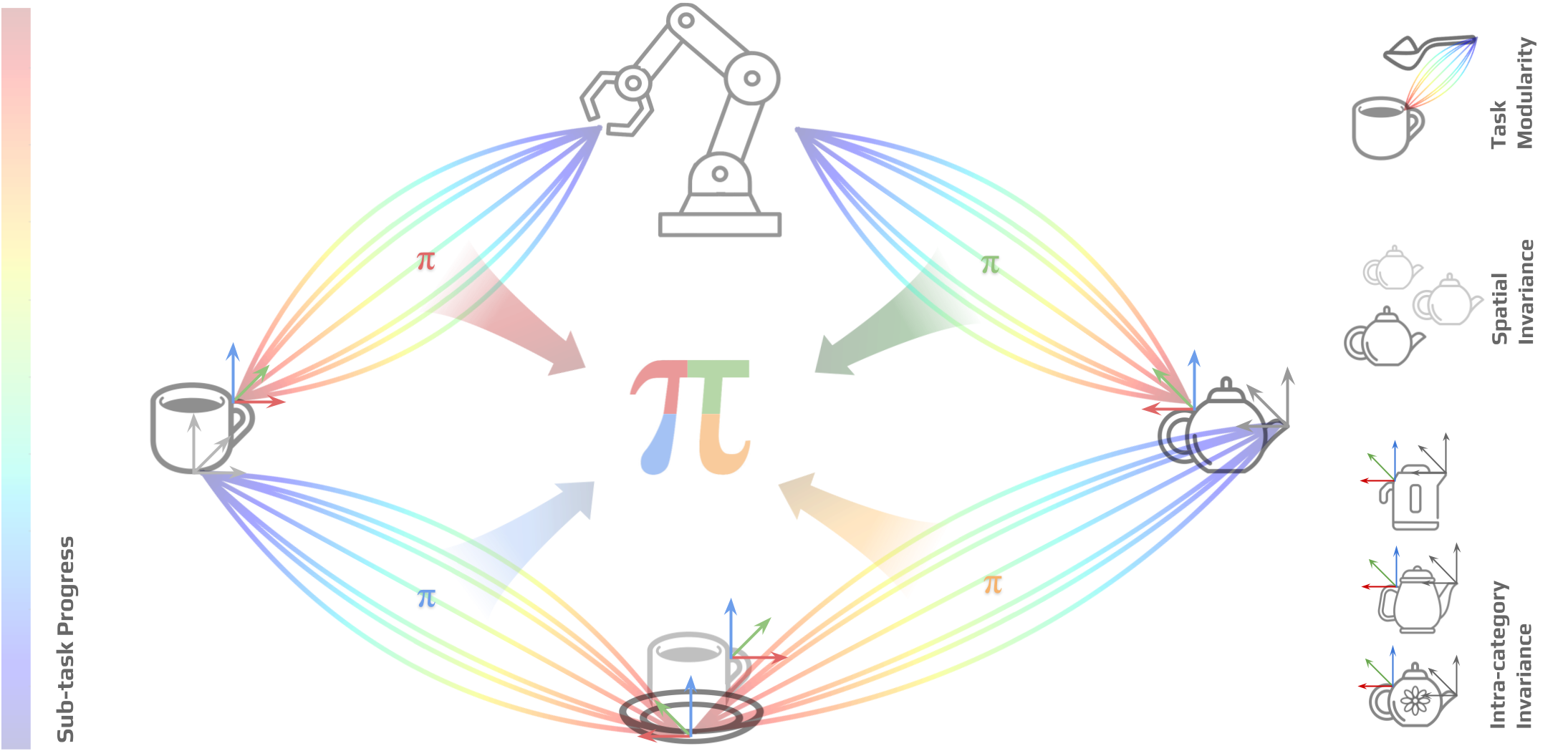
We factorise multi-object, long-horizon manipulation tasks into a series of sub-policies trained with respect to an oriented affordance-centric task frame. The relative task frame allows us to learn policies that are spatially invariant, while the specifc placement of the frames at a task-relevant affordance-centric region on an object allows for intra-category invariance. Each diffusion policy is trained to additionally predict self-progress across a sub-task enabling it to autonomously transition between sub-tasks in order to complete longer-horizon tasks.
Key Insights
Oriented Affordance Frame
We introduce the oriented affordance task frame for training sample efficient and composable diffusion policies. Using an affordance-centric task frame for policy learning enables spatial and intra-category generalisation. By orienting this task frame towards the tool frame of the robot at the start of each episode, we can concentrate the data support of the sub-policy around a known 'funnel axis'. This allows us to maximise the utility of only 10 demonstrations, with the ability to compose sub-policies to solve longer-horizon tasks. Empirical results additionally show that the oriented frame anchors the task frame in tasks where the object is dynamic, preventing the robot from hitting joint limit violations.

Policy Self-Progress
We introduce a simple introspective mechanism for policy learning based on the idea of predicting self-progress across a sub-task as an additional action output. This allows us to train sub-policies that can autonomously transition between sub-tasks in order to complete longer-horizon tasks without the need to train an additional arbitrator policy. Given the expressive multi-modality of diffusion policies, we found that a simple linspace() operator over the length of each demonstration served as a well-behaved signal for self-progress prediction as shown in the video.

Results
Simplifying Data Collection
We simplify data collection for long-horizon, multi-object tasks by training simpler, spatially invariant sub-policies. This approach allows us to collect demonstrations from a subset of the full workspace. The spatial invariance and state-based representation enable compositional generalisation to longer horizon tasks with more objects and spatial variations. We use fiducial markers during data collection to track affordance frames on objects which simplifies dataset processing, later replacing them with keypoint detectors and tracking algorithms. Note: All video demonstrations below use a single set of sub-policies trained from just 10 demonstrations with the objects and spatial variations shown on the right.

Long-Horizon Manipulation

We demonstrate the ability to compose the resulting sub-policies to solve long-horizon, multi-object tasks involving prehensile and non-prehensile manipulation actions such as scooping, pouring and pushing. The spatial invariance exhibited by each policy allows for generalisation to compositional variations when solving longer-horizon tasks with multiple objects.
Spatial Generalisation

All policies are trained using demonstrations collected within a small workspace. We demonstrate the ability to generalise to a wide range of spatial variations beyond this training workspace, including object and intra-object placement variations.
Intra-Category Generalisation

The specific placement of our affordance centric task frames allows us to capture the important task relevant regions on objects required for manipulation for a wide range of intra-category object variations. This allows us to abstract away from using images and learn state-based policies with the ability to generalise to a wide range of intra-category object variations from the 10 demonstrations collected on a single object category instance.
Policy Robustness
Perturbations
By training a closed-loop diffusion policy that operates on tracked affordance centric task frames, our policies can handle dynamic object disturbances during deployment.
Distractor Objects
Our simplified state representation allows us to learn policies that are robust to distractor objects in the environment.
Robot Base Movements
By training policies with respect to a relative task frame located on objects, we can learn policies that are robust to robot base movements during deployment with applicability to mobile manipulation.
Related Works
This work is motivated and enabled by the significant progress made in prior works developing generalist vision systems for keypoint extraction, pose tracking and policy learning.

Keypoint identification:
kPAM, Dense Object Nets, DINO ViT Features, D3Fields
Pose estimation and tracking:
Foundation Pose, BundleSDF
Policy Learning:
Diffusion Policy, Universal Manipulation Interface
Left: We leverage off-the-shelf foundation models for affordance frame localisation (DINO-ViT) and pose tracking (Foundation Pose) in our policy learning framework. This allows use to take advantage of the generalisation capabilities exhibited by these models for robot learning.